查看Stagehand评估
查看Stagehand评估了解不同LLM在Stagehand中的表现对比。
查看LLM使用情况及token计数
您可以通过stagehand.metrics随时查看token使用情况。
查看细粒度LLM使用情况
- TypeScript
- Python
您可以在Stagehand构造函数中设置
logInferenceToFile: true。这将把所有act、extract和observe调用记录到名为inference_summary的目录中。inference_summary目录将具有以下结构:
运行评估(Evals)
Stagehand评估是我们Stagehand团队用来测试Stagehand本身有效性的方法。 我们提供三种类型的评估:- 确定性评估 - 这些评估具有确定性,无需任何LLM推理即可运行。
- 基于LLM的评估 - 这些评估用于测试Stagehand AI原语的基础功能。
确定性评估
要运行确定性评估,只需在Stagehand代码库中执行npm run e2e命令。这将测试Stagehand中Playwright的功能,确保其按预期工作。
这些测试位于evals/deterministic目录下,会在Browserbase浏览器和本地无头Chromium浏览器上运行测试。
基于LLM的评估
要运行基于LLM的评估,可在Stagehand代码库中执行npm run evals命令。这将测试Stagehand中LLM原语的功能,确保其按预期工作。
评估分为三类:
- 动作评估 - 测试
act方法功能的评估 - 提取评估 - 测试
extract方法功能的评估 - 观察评估 - 测试
observe方法功能的评估 - 组合评估 - 综合测试
act、extract和observe方法功能的评估
配置与运行评估
您可以在evals/tasks 中查看具体的评估任务。每个评估任务根据 evals/evals.config.json 的配置被分组到不同的评估类别中。您可以在 evals/taskConfig.ts 中指定运行的模型和其他通用任务配置。
要运行特定评估任务,可以执行 npm run evals <eval> 命令,或者通过 npm run evals category <category> 运行整个类别的所有评估任务。
查看评估结果
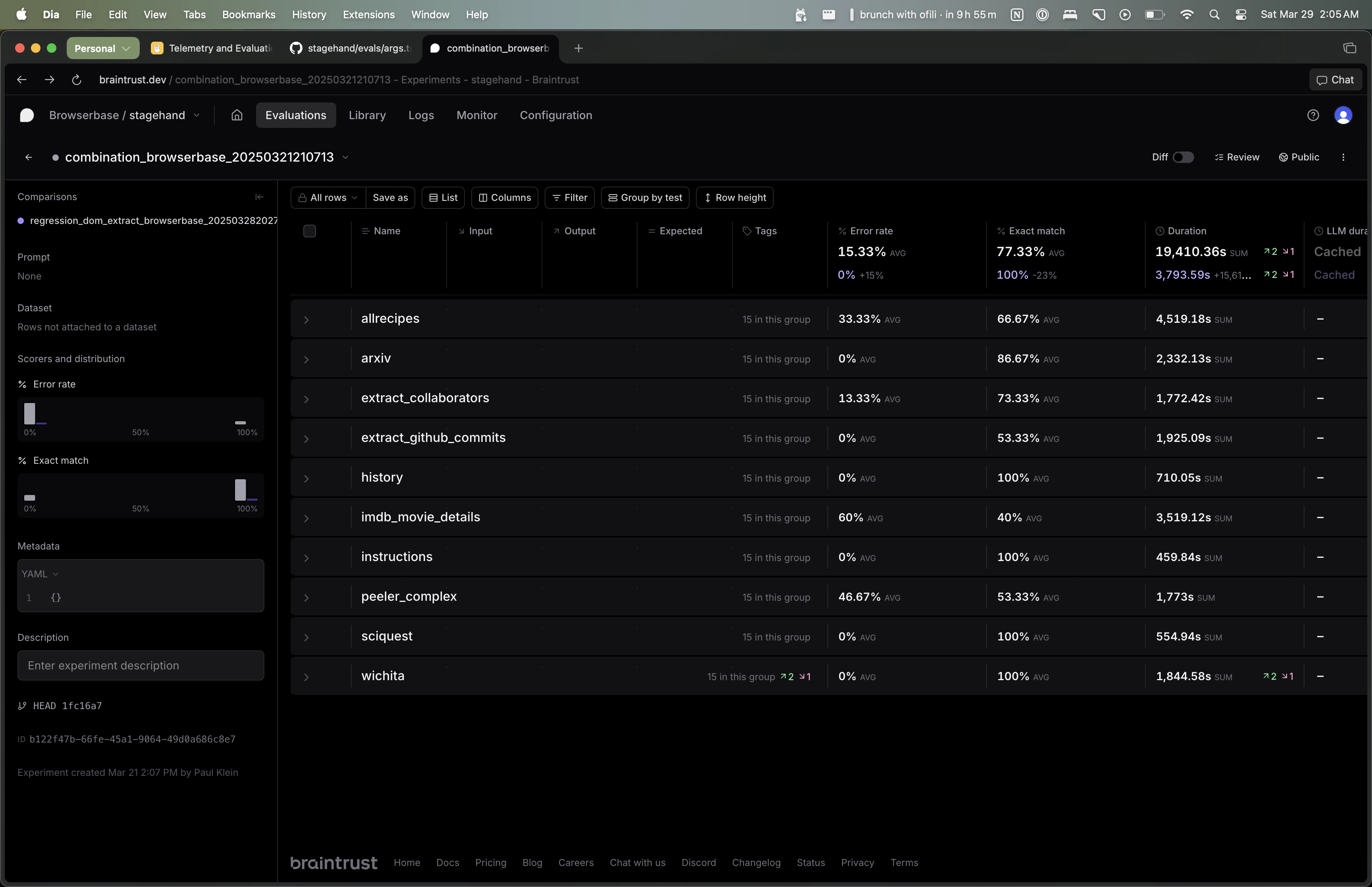
npm run evals 时终端会显示对应的 Braintrust URL,通过该链接即可查看特定评估的结果。
默认情况下,每个评估任务会对每个模型运行五次。“Exact Match”列显示评估正确的百分比,“Error Rate”列显示评估出错的百分比。
您可以使用 Braintrust 界面按模型/评估任务进行筛选,并汇总所有评估任务的结果。
添加新评估任务
要添加新评估任务,请在evals/tasks 目录创建新文件,并在 evals/evals.config.json 中将其添加到相应的类别。